








;)
;)

주요 LLM 대상 추론능력 테스트
대부분 문제 복잡해질수록 오답 증가
문제와 무관한 문장 포함 시 정확도 급락
연구진 "형식적 추론 증거 미발견"
대부분 문제 복잡해질수록 오답 증가
문제와 무관한 문장 포함 시 정확도 급락
연구진 "형식적 추론 증거 미발견"
 이미지 확대보기
이미지 확대보기해당 논문은 LLM은 지금까지 표면적인 패턴을 흉내내고 대답을 내고 있다며 진정한 추론 능력은 가지고 있지 않다고 주장하고 있다. 연구자들은 이러한 문제점을 검증하기 위해 'GSM-Symbolic'이라는 새로운 테스트 방법을 개발했다고 밝혔다. 이것은 LLM의 수학적 추론 능력을 평가하기 위한 벤치마크 데이터 세트 'GSM8K'를 개량해, 문제의 표현이나 숫자를 유연하게 바꿀 수 있도록 한 것이다. 또, 'GSM-NoOp'라고 하는, 무관계한 정보를 포함한 문제집도 작성해 LLM의 추론 능력을 평가했다.
실험 결과 오픈AI의 GPT-4o나 o1-프리뷰(o1-preview) 등의 LLM은 다른 LLM에 비해 높은 성능을 보였지만, 그래도 GSM-NoOp와 같은 함정 문제에는 여전히 취약해 진정한 추론 능력을 보유하고 있다고 보기 어려웠다.
논문에서는 LLM이 어떤 문제를 풀 때, 그 문제의 숫자나 말을 조금만 바꾸는 것만으로도 정답률이 크게 떨어졌음을 강조했다. 이를 통해 LLM이 문제의 본질을 이해하고 해결하는 것이 아니라, 훈련을 통해 습득한 데이터를 단순히 적용한 것일 뿐이라는 가능성도 시사했다.
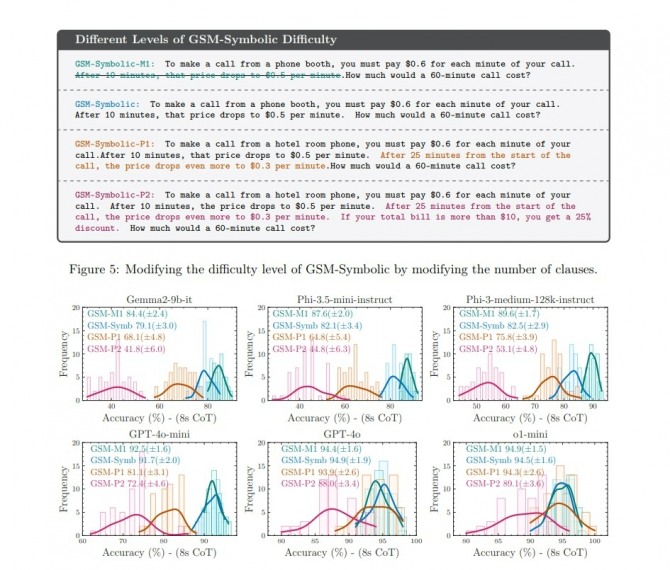
게다가 간단한 문제는 풀어도 같은 문제를 조금 복잡하게 만들면 LLM의 정답률은 하락하고 답의 편차도 커졌다고 논문은 지적했다. 가령 △GSM-Symbolic-M1: 공중전화 부스에서 전화를 걸려면 통화 1분당 0.6달러를 지불해야 한다. 10분이 지나면 이 가격은 분당 0.5달러로 떨어진다. 60분 통화 요금은 얼마인가? △GSM-Symbolic: 공중전화 부스에서 전화를 걸려면 통화 1분당 0.6달러를 지불해야 한다. 10분이 지나면 이 요금은 분당 0.5달러로 떨어진다. 60분 통화 요금은 얼마인가? △GSM-Symbolic-P1: 호텔 객실 전화로 전화를 걸려면 통화 1분당 0.6달러를 지불해야 한다. 10분이 지나면 요금이 분당 0.5달러로 떨어진다. 통화 시작 후 25분 후에는 가격은 분당 0.3달러로 더 떨어진다. 60분 통화 요금은 얼마인가? △GSM-Symbolic-P2: 호텔 객실 전화로 전화를 걸려면 통화 1분당 0.6를 지불해야 한다. 10분이 지나면 요금이 분당 0.5달러로 떨어진다. 통화 시작 후 25분 후에는 요금은 분당 0.3달러로 더 낮아진다. 총 청구금액이 10달러를 초과하는 경우 25%의 할인이 적용된다. 60분 통화 요금은 얼마인가? 같이 문제 난이도를 달리하자 구글의 젬마 2(Gemma 2)나 오픈AI의 GPT-o1 미니, 마이크로소프트의 파이-3.5(Phi-3.5)에서 조사한 결과, 모두 문제 난이도가 오르면 정답률이 떨어졌다.
위 문제처럼 실제 응답에 전혀 영향을 주지 않는 정보를 추가하면 최종 정답의 정확도가 최대 65%까지 떨어질 수 있는 것으로 나타났다. 연구팀은 "관련 없는 단어 한두 개를 바꾸거나 관련 없는 정보를 조금만 추가해도 다른 답이 나올 수 있는 이런 토대 위에서 신뢰할 수 있는 에이전트를 구축할 수 있는 방법은 없다"고 결론지었다.
문제를 제대로 이해해야 하는 수학 문제에서는 단점이 더욱 두드러졌다. 연구진은 “올리버는 금요일에 키위 44개를 딴다. 그리고 토요일에는 58개의 키위를 딴다. 일요일에는 금요일보다 두 배 많은 수의 키위를 따고 있다”고 정보를 입력하고 해당 질문과 실제 답변이 없는 문장 "일요일에 딴 키위 중 5개가 평균보다 약간 작았다라고 언급한 후 "올리버가 몇 개의 키위를 가지고 있나?"라고 물었을 때 오픈AI의 모델과 메타의 라마3-8b(Llama3-8b)는 전체 결과에서 작은 키위 5개를 뺐다.
결국 연구진은 LLM에 대해 "이름을 바꾸는 것만으로도 결과가 달라질 수 있을 정도로 취약하다"면서 “언어 모델에서 형식적 추론의 증거를 발견하지 못했다"라고 결론지었다.
이상훈 글로벌이코노믹 기자 sanghoon@g-enews.com















{kind=link}